Large Language Models in today’s era
By Eitacies
–Shanthababu Pandian
AI and Data Architect,
Introduction
A Large Language Model (LLM) is an artificial intelligence (AI) model designed to understand and generate human-like language. These models are trained on massive amounts of textual data and can perform various natural language processing (NLP) tasks. In recent years, we have all been celebrating with the tool called ChatGPT, which is the classic example of this model, and which is built along with other vital components. This large language model is named GPT-3 and 4 (Generative Pre-trained Transformer) and was developed by OpenAI. They are still enhancing this tool to support various customer needs.
Significance Characteristics
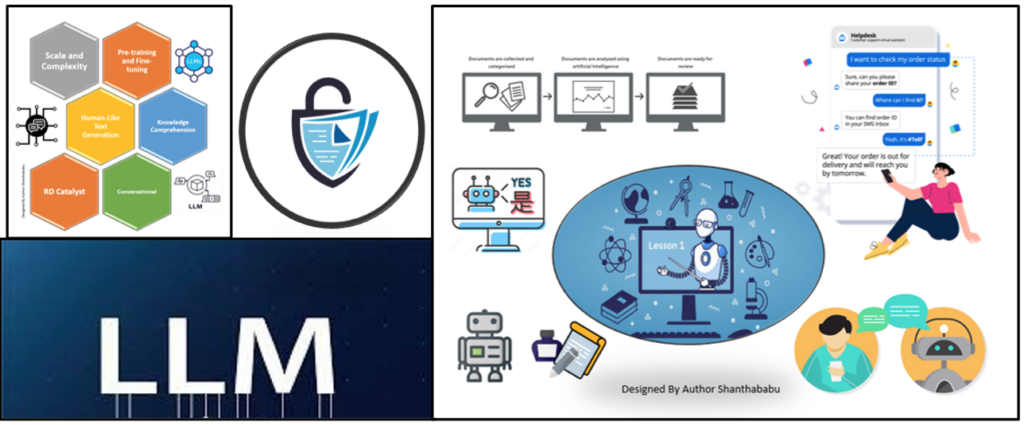
It has very unique characteristics. Let’s discuss them.
Scale and Complexity: LLMs are characterised by their enormous scale in terms of the number of parameters and the massive volume of training data. Let’s say GPT-3 has 175 billion parameters. GPT -4 has trillions of parameters and is one of the most significant LLM. This scale allows the model to capture intricate patterns and nuances in language.
Pre-training and Fine-tuning: LLMs are typically pre-trained on a vast corpus of diverse text data before being fine-tuned for specific tasks. The pre-training phase exposes the model to various linguistic patterns and contexts, enabling it to develop a rich understanding of language. Fine-tuning tailors the model for more specific applications, such as translation, summarisation, or question-answering.
Human-Like Text Generation: One of the notable capabilities of LLMs is their ability to generate coherent and contextually relevant human-like text. This makes them valuable for chatbots, content creation, and automated writing assistance applications.
Knowledge Comprehension: LLMs can comprehend and respond to questions based on their knowledge of the information present in the training data. They can provide information, answer queries, and even engage in more complex conversations, showcasing a level of language understanding that was challenging to achieve with earlier models.
Advancements in Conversational AI: LLMs have significantly advanced the field of conversational AI. They can simulate human-like conversations, understand context, and respond to user inputs more naturally and contextually appropriately.
Research and Development Catalyst: Large Language Models have become catalysts for research and development in the broader field of AI. They set benchmarks for language understanding and generation tasks, driving innovation and inspiring the growth of more sophisticated models.
Challenges and Ethical Considerations: The development of large language models has raised concerns regarding ethical considerations. Issues such as bias in language, potential misuse for generating misleading information, and the environmental impact of training such large models have become topics of discussion in the AI community.
While Large Language Models exhibit impressive capabilities, ongoing research focuses on addressing challenges, refining their behaviour, and ensuring responsible and ethical use in various applications.
Scope Of the LLM in the industry
The scope of Large Language Models (LLMs) in the industry is broad and continues to expand as organisations recognise their potential across various applications. Let’s discuss some major areas where LLMs are making a sizable influence:
Conversational AI and Chatbots:
LLMs play a crucial role in developing conversational AI systems and chatbots. They enable more natural and context-aware interactions, allowing organisations to provide enhanced customer support, virtual assistants, and interactive user experiences.
Content Generation and Copywriting: LLMs are employed for content generation, including articles, blogs, marketing copy, and creative content. They can assist content creators by suggesting ideas, generating drafts, and providing language support.
Automated Question-Answering Systems:
LLMs are utilised in question-answering systems, enabling users to pose questions in natural language and receive contextually relevant answers. This has applications in customer support, educational platforms, and information retrieval systems.
Language Translation Services:
Large Language Models enhance the accuracy and fluency of language translation services. They can translate text between multiple languages with improved contextual understanding, contributing to more effective cross-language communication.
Code Generation and Programming Assistance:
LLMs are explored for generating code snippets, assisting developers in programming tasks, and providing natural language interfaces for programming. This can enhance productivity and support developers in writing code more efficiently.
Clinical Natural Language Processing (cNLP) in Healthcare:
LLMs are being applied in healthcare for clinical natural language processing tasks. They assist in extracting relevant information from medical records, supporting clinical decision-making, and improving the efficiency of healthcare workflows.
Financial Analysis and Reporting:
LLMs contribute to financial analysis by automating the generation of reports, summarising financial news, and extracting insights from textual data. They help in digesting vast amounts of financial information for better decision-making.
Legal Document Analysis:
In the legal industry, LLMs are used for document analysis, summarisation, and legal research. They can assist legal professionals in reviewing and summarising large volumes of legal texts.
Education and E-Learning:
LLMs are employed in educational technology to create intelligent tutoring systems, generate educational content, and provide personalised learning experiences. They support language-based tasks in e-learning platforms.
Knowledge Extraction and Graph Generation:
LLMs contribute to knowledge extraction by analysing textual data and generating knowledge graphs. This aids in organizing and visualizing relationships between entities, enhancing knowledge management systems.
The scope of LLMs is continually expanding as researchers and developers explore and refine new applications. While the technology presents exciting possibilities, ethical considerations, privacy concerns, and responsible deployment are critical to address in integrating LLMs into various industries.
Challenges with Large Language Models
Large Language Models (LLMs) come with various challenges, some of which are:
Ethical Concerns and Bias:
LLMs can, by mistake, learn and maintain biases in the training data. This can lead to biased outputs, reinforcing stereotypes, and contributing to unfair and discriminatory outcomes.
Lack of Understanding:
Despite their impressive language generation capabilities, LLMs may lack true comprehension and understanding of the context. They can produce plausible-sounding yet incorrect or nonsensical responses.
Explainability:
LLMs, especially the very large ones, are often criticized for their lack of transparency and explainability. Understanding why a model produces a specific output can be challenging, making it difficult to interpret and trust its decisions.
Data Privacy:
LLMs are trained on vast datasets, and concerns arise regarding the potential inclusion of sensitive or private information in the training data. This raises issues related to data privacy and confidentiality.
Resource Intensive Training:
LLM requires a substantial computational source and energy utilization for training purposes. This has raised environmental concerns and questions about the sustainability of training such resource-intensive models.
Overfitting and Memorization:
Large models may have a tendency to memorize specific examples from the training data, leading to overfitting. This can result in the model providing overly specific responses rather than generalizing well to new inputs.
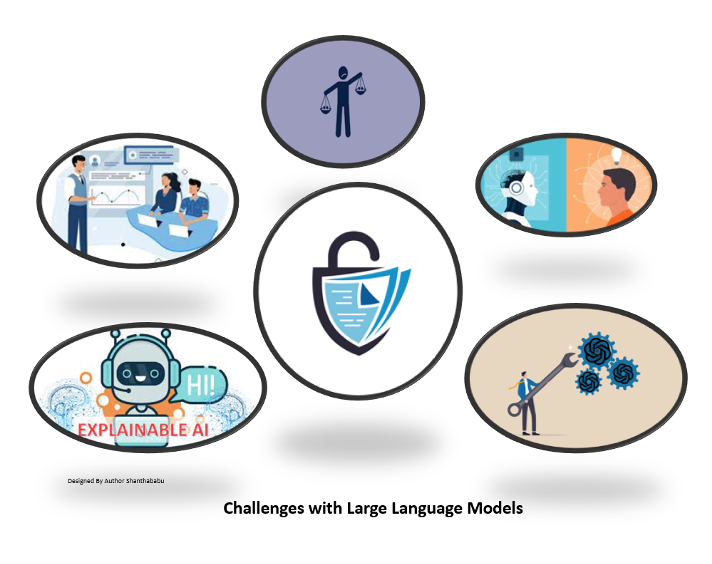
Fine-Tuning Challenges:
Fine-tuning LLMs for specific tasks may not always result in the desired behavior. The fine-tuning process can be complex, and models may exhibit unexpected behavior or generate inappropriate content.
Safety and Misuse:
There are concerns about the potential misuse of LLMs for generating misleading information, deepfakes, or other malicious purposes. Ensuring the responsible use of such powerful language models is a critical challenge.
Context Collapse:
LLMs may exhibit context collapse, where they generate responses that are generic and fail to maintain a coherent conversation. This challenge is particularly evident in long conversations or interactions where context is crucial.
Continual Learning and Adaptation:
LLMs may struggle with continual learning and adapting to dynamic contexts. They are typically trained on static datasets and may not seamlessly integrate new information or adapt to evolving language use.
Deployment in Resource-Constrained Environments:
The resource-intensive nature of large language models can pose challenges when deploying them in resource-constrained environments, limiting their accessibility and practical applicability.
Addressing these challenges requires ongoing research and development in the field of artificial intelligence. Researchers and practitioners are actively working to enhance LLMs’ transparency, fairness, and robustness while ensuring their responsible and ethical use in various applications.
Conclusion
So far, we have discussed the scope and use cases of Large Language Models (LLMs), which are undoubtedly extensive and impactful across various industries. LLMs, exemplified by models like GPT-3 and 4, have demonstrated remarkable natural language understanding, generation, and processing capabilities. Critical takeaways regarding LLMs’ scope and use cases are Versatility Across Industries, Conversational AI Advancements, Knowledge Extraction, and Graph Generation. While LLMs present exciting opportunities for innovation, it is crucial to approach their deployment with ethical considerations, transparency, and responsible practices to address potential challenges and ensure positive societal impact.
#AI#ArtificialIntelligence#ConversationalAI#DataPrivacy#DataScience#Eitacies#EitaciesImpact#EthicalAI#FutureTech#GPT3#GPT4#InnovationInTech#KnowledgeGraph#LargeLanguageModels#MachineLearning#NaturalLanguageProcessing#TechInnovation#TechnologyTrends
